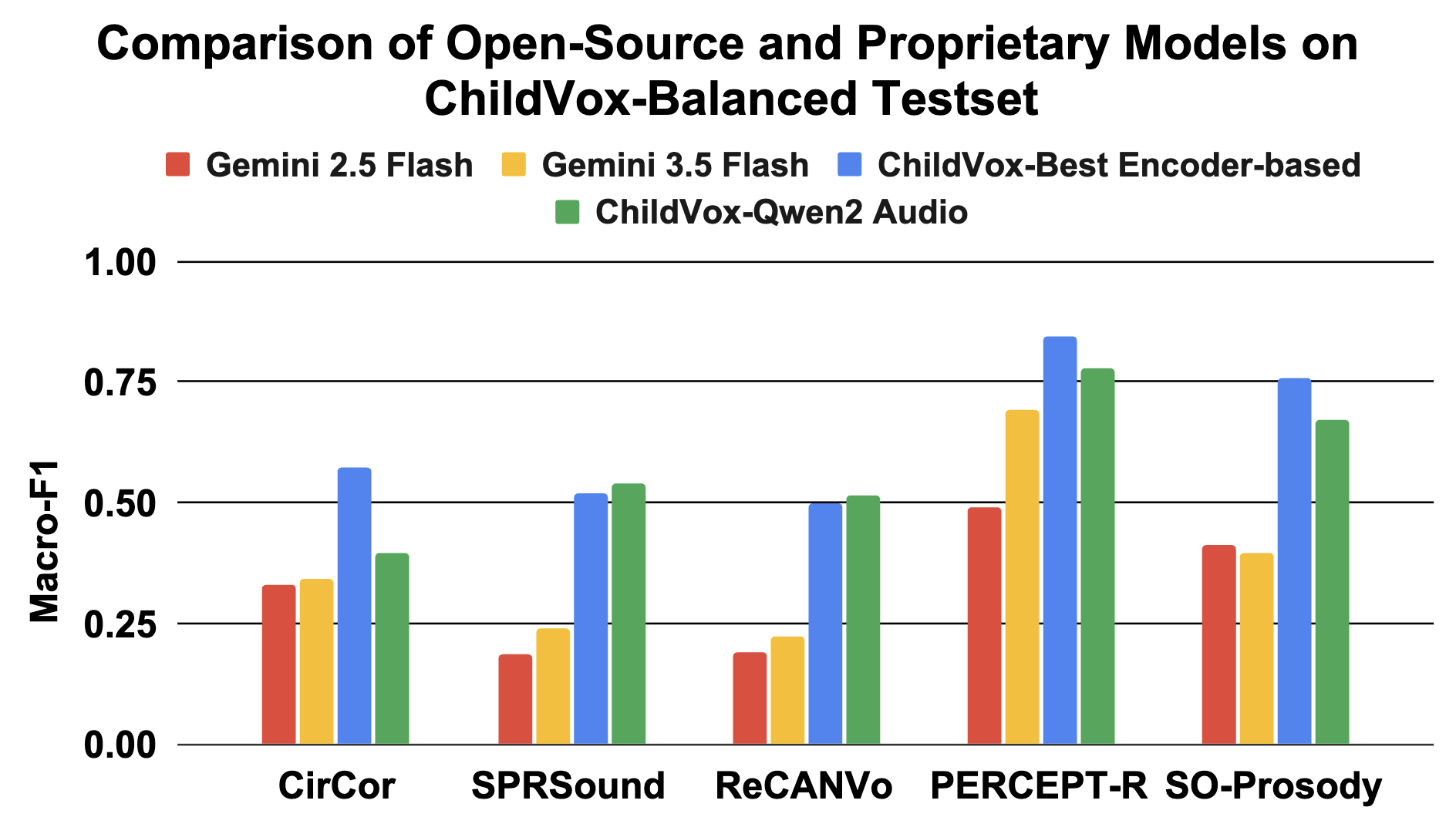
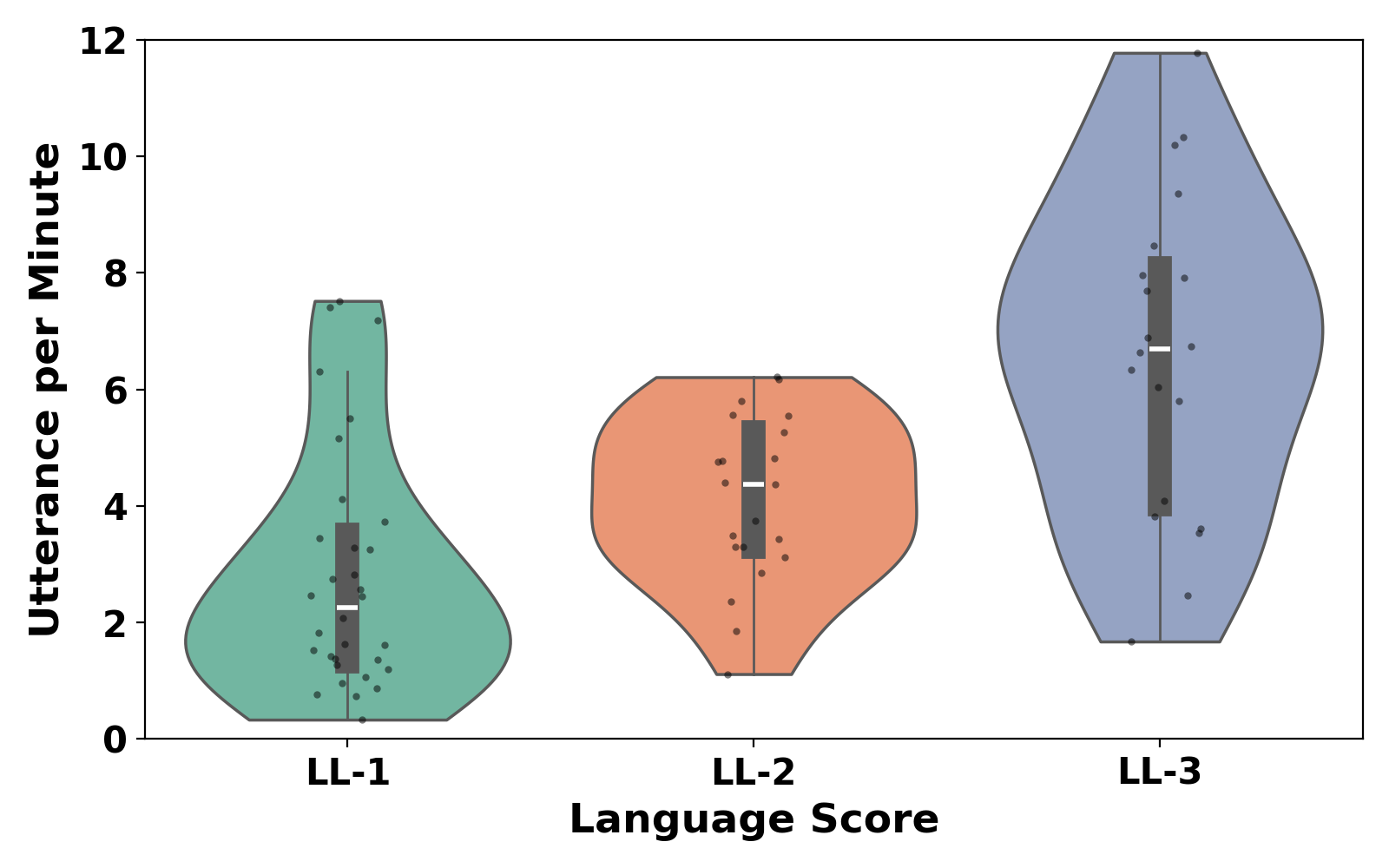
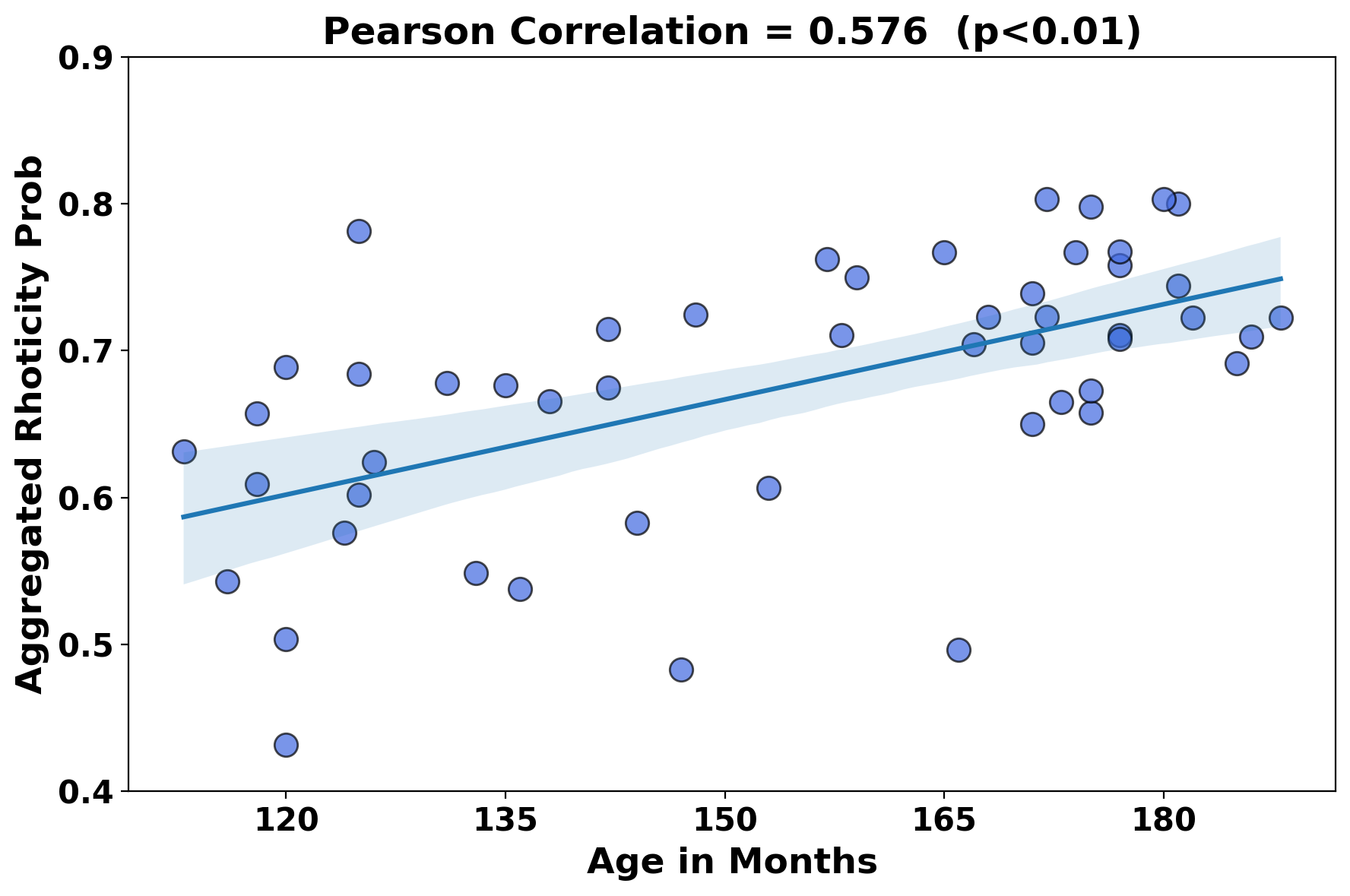
ChildVox integrates more than 15 child-centered audio and speech datasets into one computational benchmark. The benchmark includes publicly available pediatric heart, lung, and vocalization corpora alongside two in-house naturalistic interaction datasets (NLS and ADOS2-Mod3).
Physiological Sounds
Birth (and across Life)
Cardiac and respiratory sounds carry the clinical signals - before any spoken word or vocolization.
Vocalizations
Infancy
Cries, laughter, whimpers - non-linguistic events with rich affective meaning.
Canonical Syllables
Toddler
Babbling, proto-speech, and the emerging spoken language skills.
Speech
School-age
Pronunciation, fluency, prosody, intelligibility, and conversational ASR.
ChildVox is a unified benchmark covering the full developmental trajectory through which children "express" themselves, ranging from physiological sounds at birth, through infant vocalizations and toddler babble, to school-age speech.